 Fundamentals
Fundamentals
Start by building a "Hello world" example.
To install Kestra, follow the Quickstart Guide or check the detailed Installation Guide.
Flows
Flows are defined in a declarative YAML syntax to keep the orchestration code portable and language-agnostic.
Each flow consists of three required components: id, namespace and tasks:
idrepresents the name of the flownamespacecan be used to separate development and production environmentstasksis a list of tasks that will be executed in the order they are defined
Here are those three components in a YAML file:
id: getting_started
namespace: company.team
tasks:
- id: hello_world
type: io.kestra.plugin.core.log.Log
message: Hello World!
The id of a flow must be unique within a namespace. For example:
- ✅ you can have a flow named
getting_startedin thecompany.team1namespace and another flow namedgetting_startedin thecompany.team2namespace. - ❌ you cannot have two flows named
getting_startedin thecompany.teamnamespace at the same time.
The combination of id and namespace serves as a unique identifier for a flow.
Namespaces
Namespaces are used to group flows and provide structure. Keep in mind that the allocation of a flow to a namespace is immutable. Once a flow is created, you cannot change its namespace. If you need to change the namespace of a flow, create a new flow with the desired namespace and delete the old flow.
Labels
To add another layer of organization, you can use labels, allowing you to group flows using key-value pairs.
Description(s)
You can optionally add a description property to keep your flows documented. The description is a string that supports markdown syntax. That markdown description will be rendered and displayed in the UI.
Not only flows can have a description. You can also add a description property to tasks and triggers to keep all the components of your workflow documented.
Here is the same flow as before, but this time with labels and descriptions:
id: getting_started
namespace: company.team
description: |
# Getting Started
Let's `write` some **markdown** - [first flow](https://t.ly/Vemr0) 🚀
labels:
owner: rick.astley
project: never-gonna-give-you-up
tasks:
- id: hello_world
type: io.kestra.plugin.core.log.Log
message: Hello World!
description: |
## About this task
This task will print "Hello World!" to the logs.
Learn more about flows in the Flows section.
Tasks
Tasks are atomic actions in your flows. You can design your tasks to be small and granular, e.g. fetching data from a REST API or running a self-contained Python script. However, tasks can also represent large and complex processes, e.g. triggering containerized processes or long-running batch jobs (e.g. using dbt, Spark, AWS Batch, Azure Batch, etc.) and waiting for their completion.
The order of task execution
Tasks are defined in the form of a list. By default, all tasks in the list will be executed sequentially — the second task will start as soon as the first one finishes successfully.
Kestra provides additional customization allowing to run tasks in parallel, iterating (sequentially or in parallel) over a list of items, or to allow failure of specific tasks. Those are called Flowable tasks because they define the flow logic.
A task in Kestra must have an id and a type. Other properties depend on the task type. You can think of a task as a step in a flow that should execute a specific action, such as running a Python or Node.js script in a Docker container, or loading data from a database.
tasks:
- id: python
type: io.kestra.plugin.scripts.python.Script
docker:
image: python:slim
script: |
print("Hello World!")
Autocompletion
Kestra supports hundreds of tasks integrating with various external systems. Use the shortcut CTRL + SPACE on Windows/Linux or fn + control + SPACE on Mac to trigger autocompletion listing available tasks or properties of a given task.
If you want to comment out some part of your code, use the CTRL or ⌘ + K + C shortcut, and to uncomment it, use CTRL or ⌘ + K + U. To remember it, C stands for comment and U stands for uncomment. All available keyboard shortcuts are listed upon right-clicking anywhere in the code editor.

Supported task types
Let's look at supported task types.
Core
Core tasks from the io.kestra.plugin.core.flow category are commonly used to control the flow logic. You can use them to declare which processes should run in parallel or sequentially. You can specify conditional branching, iterating over a list of items, pausing or allowing certain tasks to fail without failing the execution.
Scripts
Script tasks are used to run scripts in Docker containers or local processes. You can use them to run Python, Node.js, R, Julia, or any other script. You can also use them to execute a series of commands in Shell or PowerShell. Check the Script tasks page for more details.
Internal Storage
Tasks from the io.kestra.plugin.core.storage category, along with Outputs, are used to interact with the internal storage. Kestra uses internal storage to pass data between tasks. You can think of internal storage as an S3 bucket. In fact, you can use your private S3 bucket as internal storage. This storage layer helps avoid proliferation of connectors. For example, you can use the Postgres plugin to extract data from a Postgres database and load it to the internal storage. Other task(s) can read that data from internal storage and load it to other systems such as Snowflake, BigQuery, or Redshift, or process it using any other plugin, without requiring point to point connections between each of them.
State Store
Internal storage is mainly used to pass data within a single flow execution. If you need to pass data between different flow executions, you can use the State Store. The tasks Set, Get and Delete from the io.kestra.plugin.core.state category allow you to persist files between executions (even across namespaces). For example, if you are using dbt, you can leverage the State Store to persist the manifest.json file between executions and implement the slim CI pattern.
⚡️ Plugins
Apart from core tasks, the plugins library provides a wide range of integrations. Kestra has built-in plugins for data ingestion, data transformation, interacting with databases, object stores, or message queues, and the list keeps growing with every new release. On top of that, you can also create your own plugins to integrate with any system or programming language.
Create and run your first flow
Now, let's create and run your first flow. On the left side of the screen, click on the Flows menu. Then, click on the Create button.
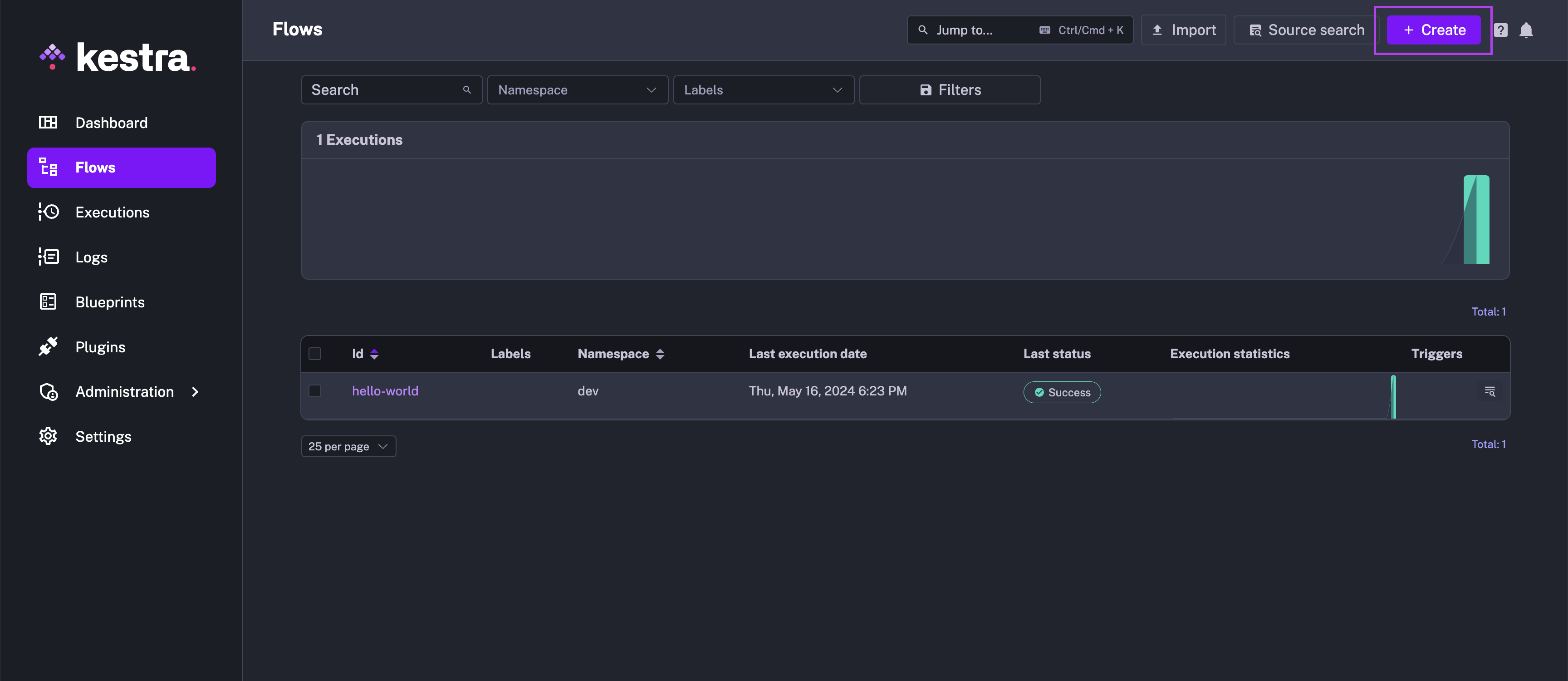
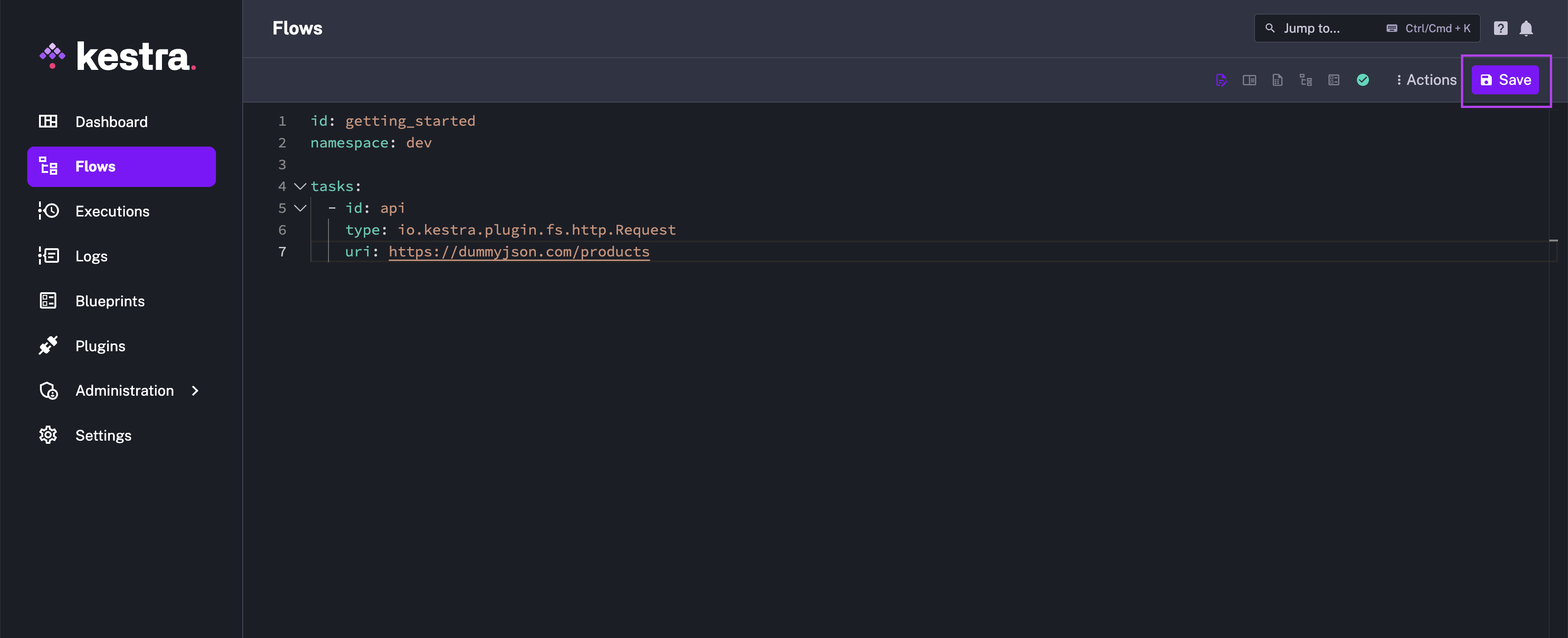
Paste the following code to the Flow editor:
id: getting_started
namespace: company.team
tasks:
- id: api
type: io.kestra.plugin.core.http.Request
uri: https://dummyjson.com/products
Then, hit the Save button.
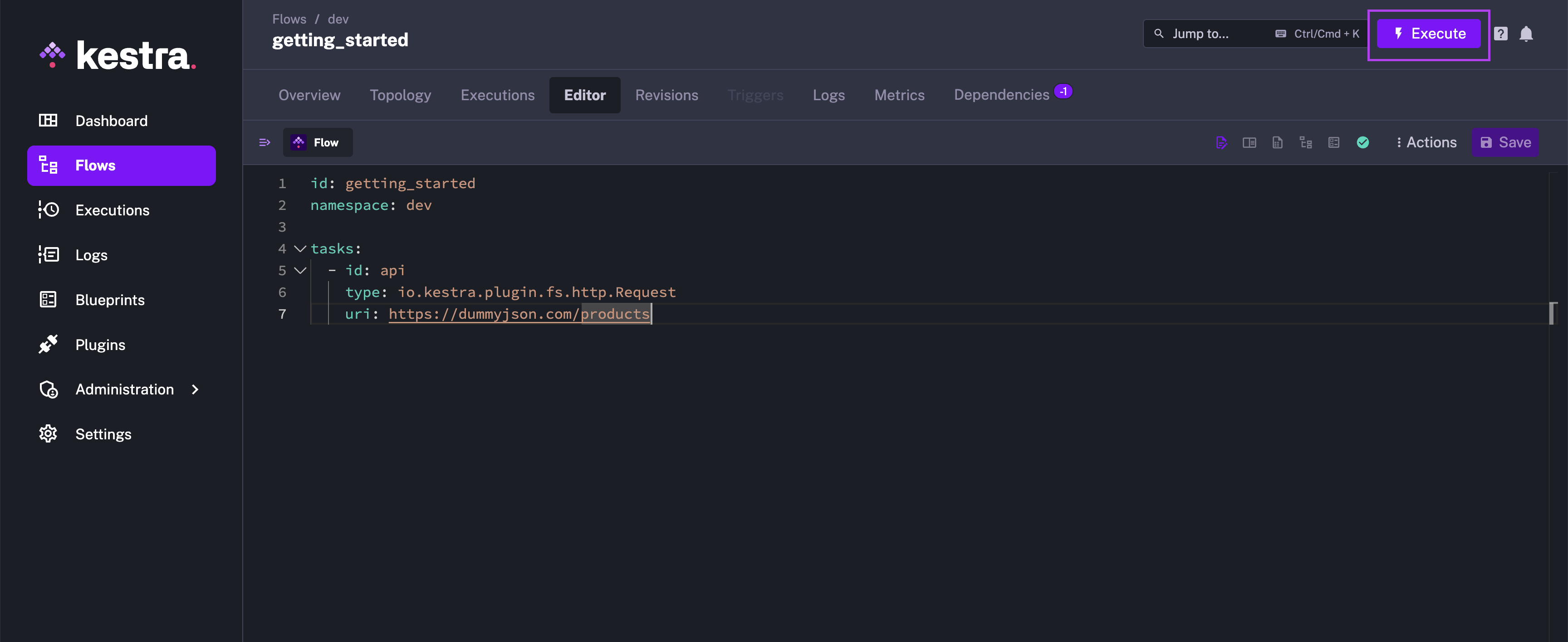
This flow has a single task that will fetch data from the dummyjson API. Let's run it!
Was this page helpful?