 Outputs
Outputs
Outputs allow you to pass data between tasks and flows.
Don't use Outputs to fetch any sensitive data (passwords, secrets, API tokens, ...). Fetching Secrets from an external Secrets Manager via a task imposes a significant security risk. All data fetched via outputs is stored in clear text in multiple places (incl. the backend database, internal storage, logs, API requests). For secure handling of secrets, use exclusively Secrets. Kestra EE and Kestra Cloud offer reliable secrets management including native integrations with various Secrets Managers.
What are outputs
A workflow execution can generate outputs. Outputs are stored in the flow's execution context (i.e. in memory) and can be used by all downstream tasks and flows.
Outputs can have multiple attributes — check the documentation of each task to see their output attributes.
You can retrieve outputs from other tasks within all dynamic properties.
Using outputs
Here is how to use the output of the produce-output task in the use-output task. Here we use the Return task that has one output attribute named value.
id: task_outputs_example
namespace: company.team
tasks:
- id: produce-output
type: io.kestra.plugin.core.debug.Return
format: my output {{ execution.id }}
- id: use-output
type: io.kestra.plugin.core.log.Log
message: The previous task output is {{ outputs['produce-output'].value }}
In the example above, the first task produces an output based on the task property format. This output attribute is then used in the second task message property.
The expression {{ outputs['produce-output'].value }} references the previous task output attribute. You can read more about the expression syntax on the Using Expressions page.
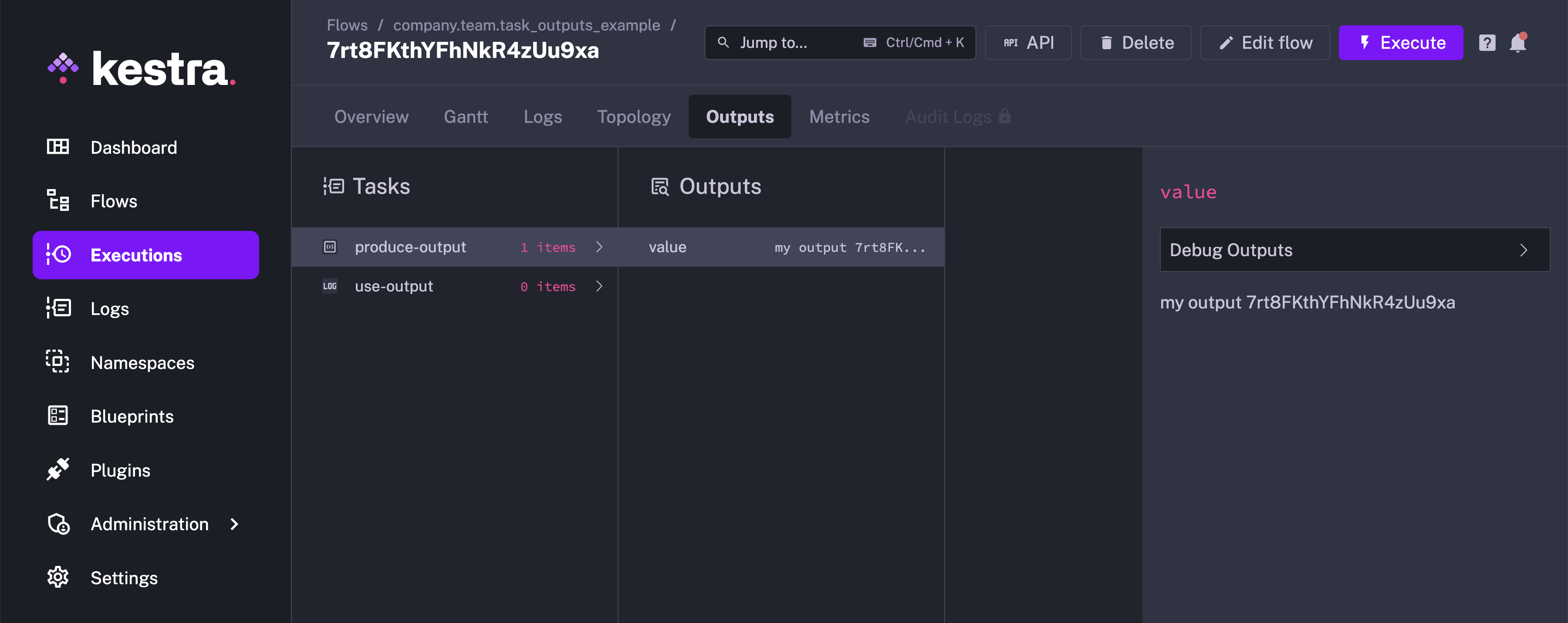
In the example above, the Return task produces an output attribute value. Every task produces different output attributes. You can look at each task outputs documentation or use the Outputs tab of the Executions page to find out about specific task output attributes.
The Outputs tab will have the output for produce-output task. There is no output for use-output task as it only logs a message.
In the next example, we can see a file is passed between an input and a task, where the task generates a new file as an output:
id: bash_with_files
namespace: company.team
description: This flow shows how to pass files between inputs and tasks in Shell scripts.
inputs:
- id: file
type: FILE
tasks:
- id: rename
type: io.kestra.plugin.scripts.shell.Commands
commands:
- mv file.tmp output.tmp
inputFiles:
file.tmp: "{{ inputs.file }}"
outputFiles:
- "*.tmp"
Since 0.14, Outputs are no longer rendered recursively. You can read more about this change and how to change this behaviour here.
Internal storage
Each task can store data in Kestra's internal storage. If an output attribute is stored in internal storage, the attribute will contain a URI that points to a file in the internal storage. This output attribute could be used by other tasks to access the stored data.
The following example stores the query results in internal storage, then accesses it in the write-to-csv task:
id: output-sample
namespace: company.team
tasks:
- id: output-from-query
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
SELECT * FROM `bigquery-public-data.wikipedia.pageviews_2023`
WHERE DATE(datehour) = current_date()
ORDER BY datehour desc, views desc
LIMIT 10
store: true
- id: write-to-csv
type: io.kestra.plugin.serdes.csv.IonToCsv
from: "{{ outputs['output-from-query'].uri }}"
Dynamic variables (Each tasks)
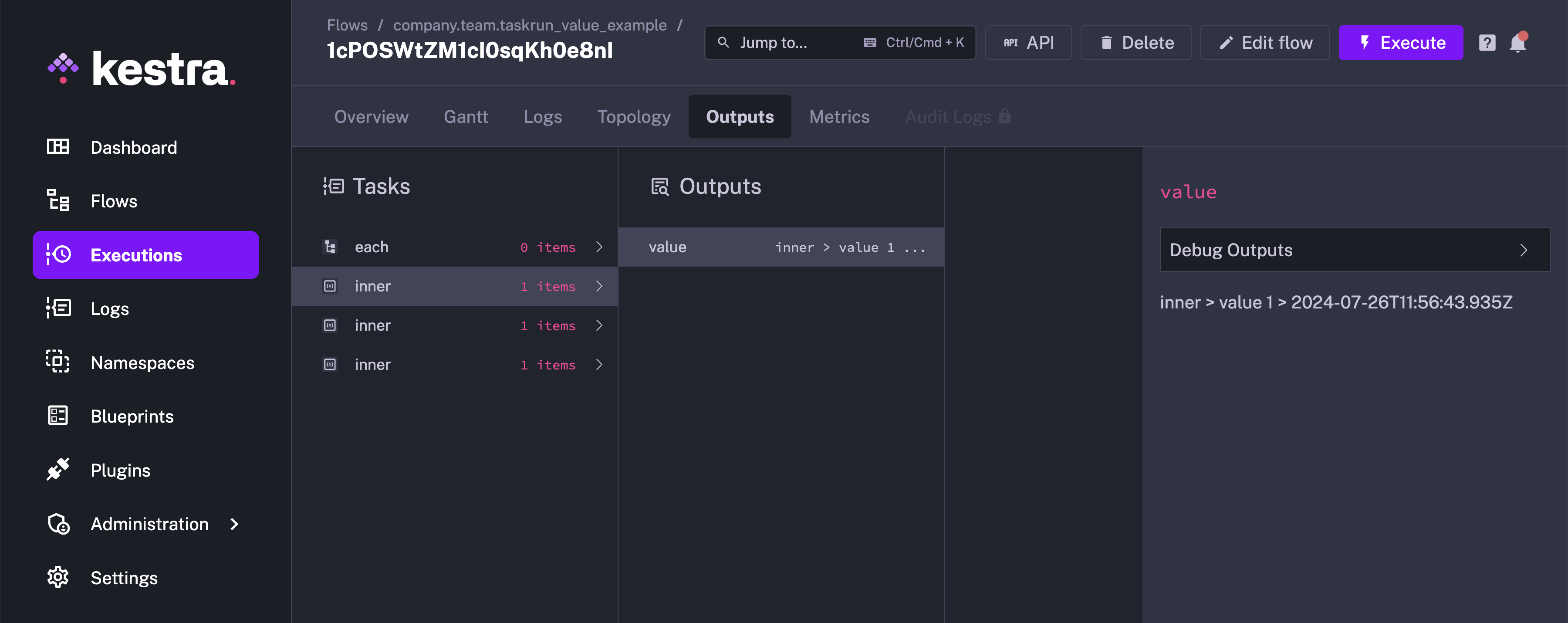
Current taskrun value
In dynamic flows (using "Each" loops for example), variables will be passed to task dynamically. You can access the current taskrun value with {{ taskrun.value }} like this:
id: taskrun_value_example
namespace: company.team
tasks:
- id: each
type: io.kestra.plugin.core.flow.EachSequential
value: ["value 1", "value 2", "value 3"]
tasks:
- id: inner
type: io.kestra.plugin.core.debug.Return
format: "{{ task.id }} > {{ taskrun.value }} > {{ taskrun.startDate }}"
The Outputs tab would contain the output for each of the inner task.
Loop over a list of JSON objects
On loop, the value is always a JSON string, so the {{ taskrun.value }} is the current element as JSON string. If you want to access properties, you need to use the json function to have a proper object and to access each property easily.
id: loop_sequentially_over_list
namespace: company.team
tasks:
- id: each
type: io.kestra.plugin.core.flow.EachSequential
value:
- {"key": "my-key", "value": "my-value"}
- {"key": "my-complex", "value": {"sub": 1, "bool": true}}
tasks:
- id: inner
type: io.kestra.plugin.core.debug.Return
format: "{{ json({taskrun.value).key }} > {{ json({taskrun.value).value }}"
Specific outputs for dynamic tasks
Dynamic tasks are tasks that will run other tasks a certain number of times. A dynamic task will run multiple iterations of a set of sub-tasks.
For example, EachSequential and EachParallel produce other tasks dynamically depending on their value property.
It is possible to reach each iteration output of dynamic tasks by using the following syntax:
id: output_sample
namespace: company.team
tasks:
- id: each
type: io.kestra.plugin.core.flow.EachSequential
value: ["s1", "s2", "s3"]
tasks:
- id: sub
type: io.kestra.plugin.core.debug.Return
format: "{{ task.id }} > {{ taskrun.value }} > {{ taskrun.startDate }}"
- id: use
type: io.kestra.plugin.core.debug.Return
format: "Previous task produced output: {{ outputs.sub.s1.value }}"
The outputs.sub.s1.value variable reaches the value of the sub task of the s1 iteration.
Previous task lookup
It is also possible to locate a specific dynamic task by its value:
id: dynamic_looping
namespace: company.team
tasks:
- id: each
type: io.kestra.plugin.core.flow.EachSequential
value: ["value 1", "value 2", "value 3"]
tasks:
- id: inner
type: io.kestra.plugin.core.debug.Return
format: "{{ task.id }}"
- id: end
type: io.kestra.plugin.core.debug.Return
format: "{{ task.id }} > {{ outputs.inner['value 1'].value }}"
It uses the format outputs.TASKID[VALUE].ATTRIBUTE. The special bracket [] in [VALUE] is called the subscript notation; it enables using special chars like space or '-' in task identifiers or output attributes.
Lookup in sibling tasks
Sometimes, it can be useful to access previous outputs on the current task tree, what is called sibling tasks.
If the task tree is static, for example when using the Sequential task, you can use the {{ outputs.sibling.value }} notation where siblingis the identifier of the sibling task.
If the task tree is dynamic, for example when using the EachSequential task, you need to use {{ sibling[taskrun.value] }} to access the current tree task. taskrun.value is a special variable that holds the current value of the EachSequential task.
For example:
id: loop_with_sibling_tasks
namespace: company.team
tasks:
- id: each
type: io.kestra.plugin.core.flow.EachSequential
value: ["value 1", "value 2", "value 3"]
tasks:
- id: first
type: io.kestra.plugin.core.debug.Return
format: "{{ task.id }}"
- id: second
type: io.kestra.plugin.core.debug.Return
format: "{{ outputs.first[taskrun.value].value }}"
- id: end
type: io.kestra.plugin.core.debug.Return
format: "{{ task.id }} > {{ outputs.second['value 1'].value }}"
When there are multiple levels of EachSequential tasks, you can use the parents variable to access the taskrun.value of the parent of the current EachSequential. For example, for two levels of EachSequential you can use outputs.sibling[parents[0].taskrun.value][taskrun.value].value.
The latter can become very complex when parents exist (multiple imbricated EachSequential). For this, you can use the special currentEachOutput function. No matter the number of parents, the following example will retrieve the correct output attribute: currentEachOutput(outputs.sibling).value thanks to this function.
Accessing sibling task outputs is impossible on Parallel or EachParallel as they run tasks in parallel.
Pass data between flows using flow outputs
Since 0.15.0, the flow can also produce strongly typed outputs simply by defining them in the flow file. Here is an example of a flow that produces an output:
id: flow_outputs
namespace: company.team
tasks:
- id: mytask
type: io.kestra.plugin.core.debug.Return
format: this is a task output used as a final flow output
outputs:
- id: final
type: STRING
value: "{{ outputs.mytask.value }}"
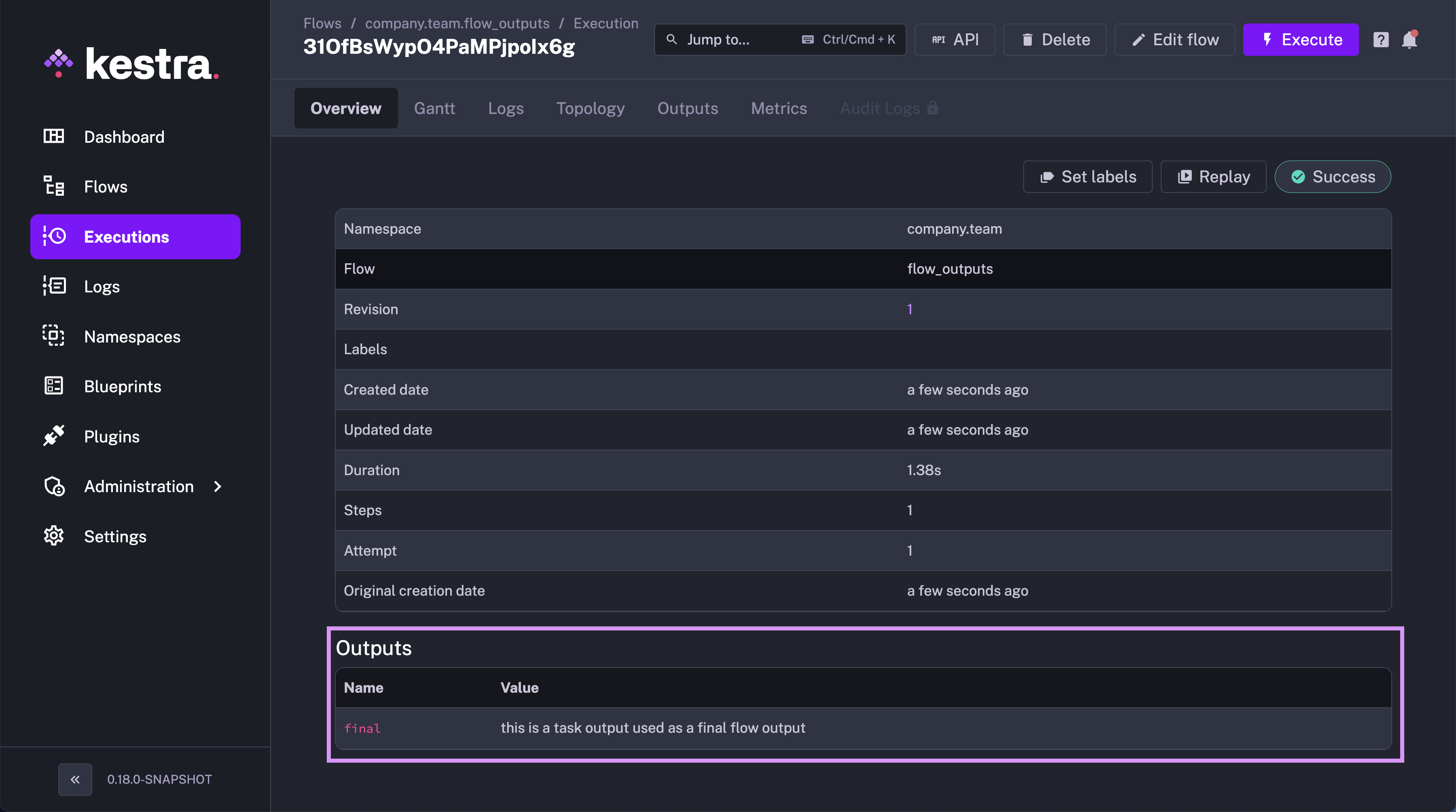
You can see that outputs are defined as a list of key-value pairs. The id is the name of the output attribute (must be unique within a flow), and the value is the value of the output. You can also add a description to the output.
You will see the output of the flow on the Executions page in the Overview tab.
Here is how you can access the flow output in the parent flow:
id: parent_flow
namespace: company.team
tasks:
- id: subflow
type: io.kestra.plugin.core.flow.Subflow
flowId: flow_outputs
namespace: company.team
wait: true
- id: log_subflow_output
type: io.kestra.plugin.core.log.Log
message: "{{ outputs.subflow.outputs.final }}"
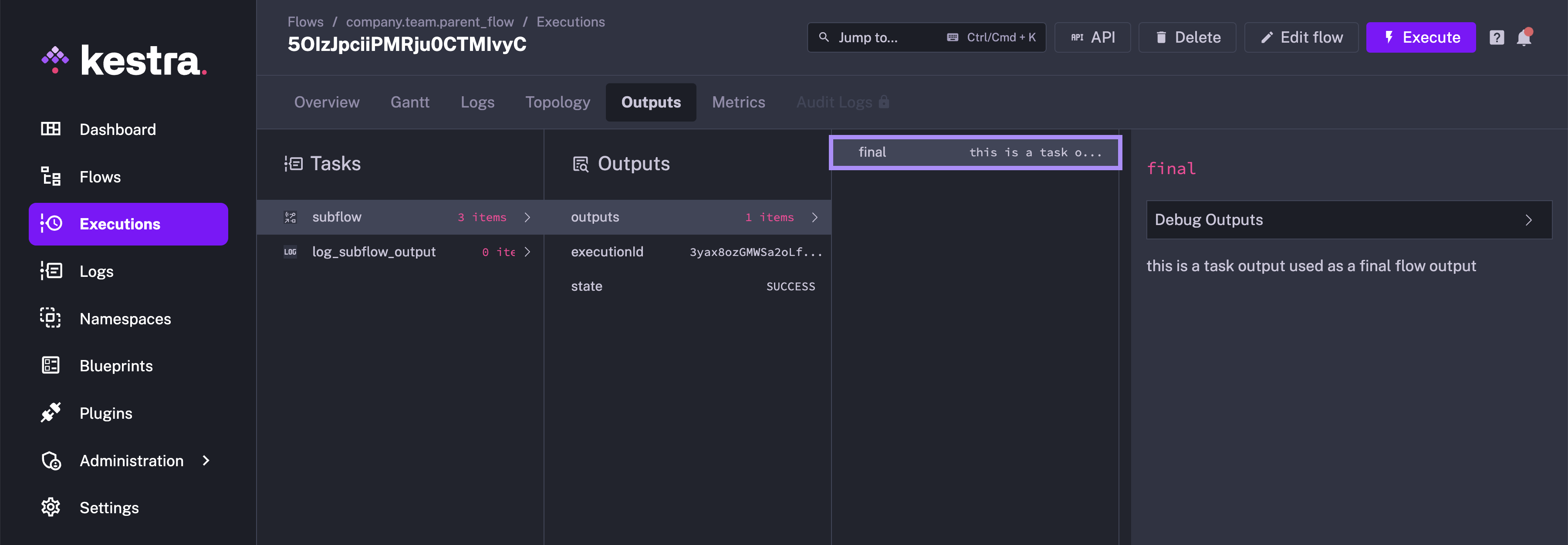
In the example above, the subflow task produces an output attribute final. This output attribute is then used in the log_subflow_output task.
Note how the outputs are set twice within the "{{outputs.subflow.outputs.final}}":
- once to access outputs of the
subflowtask - once to access the outputs of the subflow itself — specifically, the
finaloutput.
Here is what you will see in the Outputs tab of the Executions page in the parent flow:
Outputs Preview
Kestra provides preview option for output files that get stored on Kestra internal storage. Lets see this with the help of the following flow:
id: get-employees
namespace: company.team
tasks:
- id: download
type: io.kestra.plugin.core.http.Download
uri: https://huggingface.co/datasets/kestra/datasets/raw/main/ion/employees.ion
On executing this flow, the file will be downloaded onto the Kestra internal storage. When you go to the Outputs tab for this execution, the uri attribute of the download task contains the file location on Kestra's internal storage, and would have a Download and a Preview button.
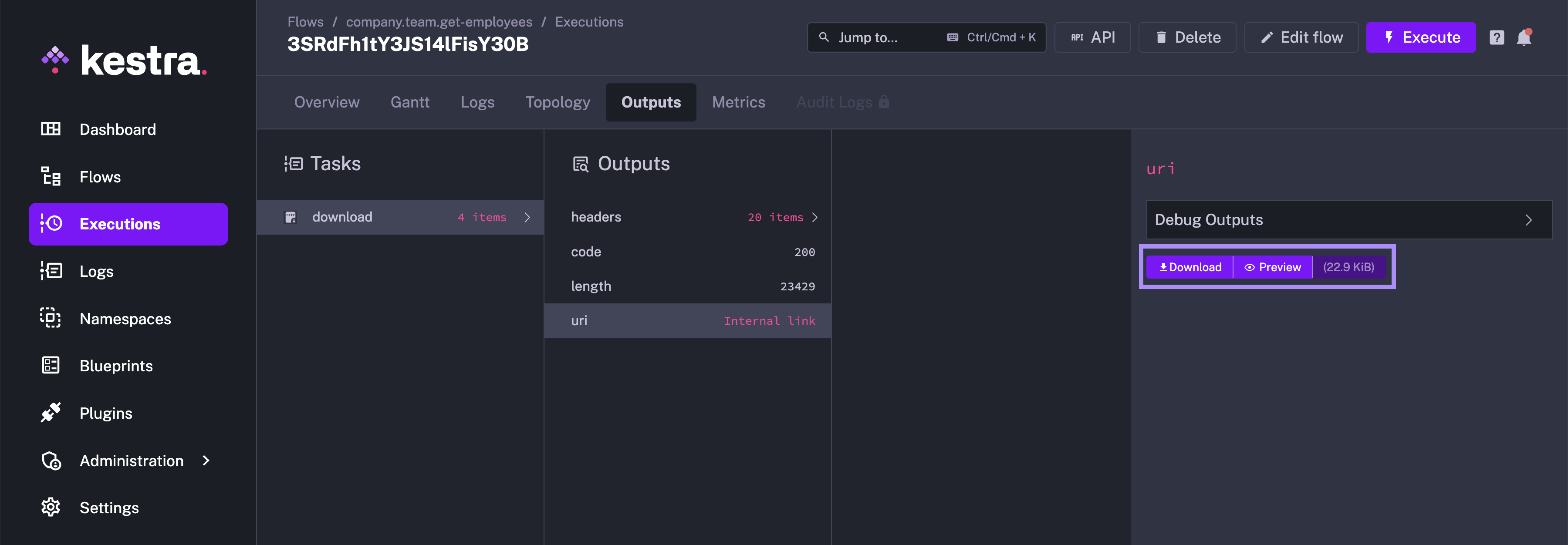
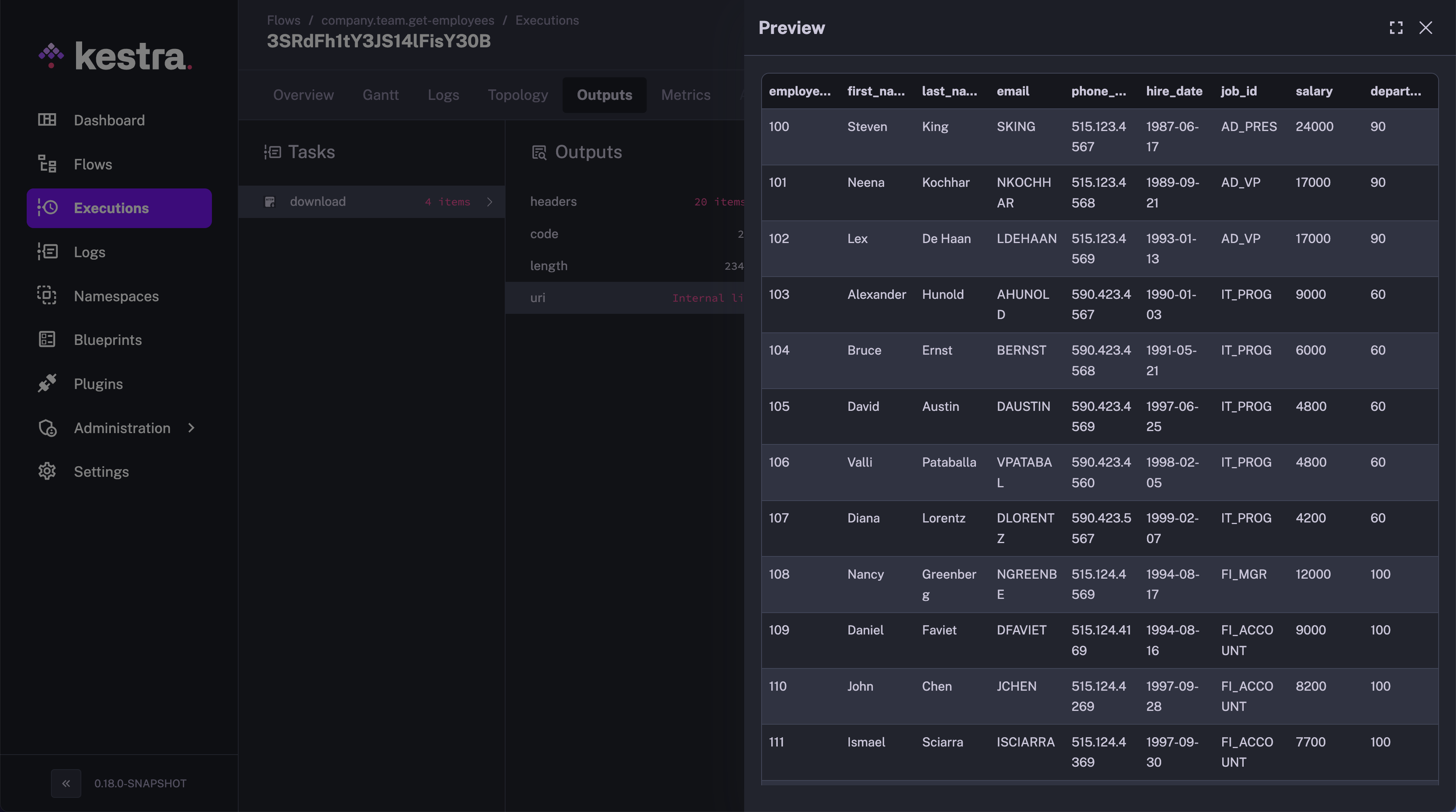
On clicking the Preview button, you can preview the contents of the file in a tabular format, making it extremely easy to check the contents of the file without downloading it.
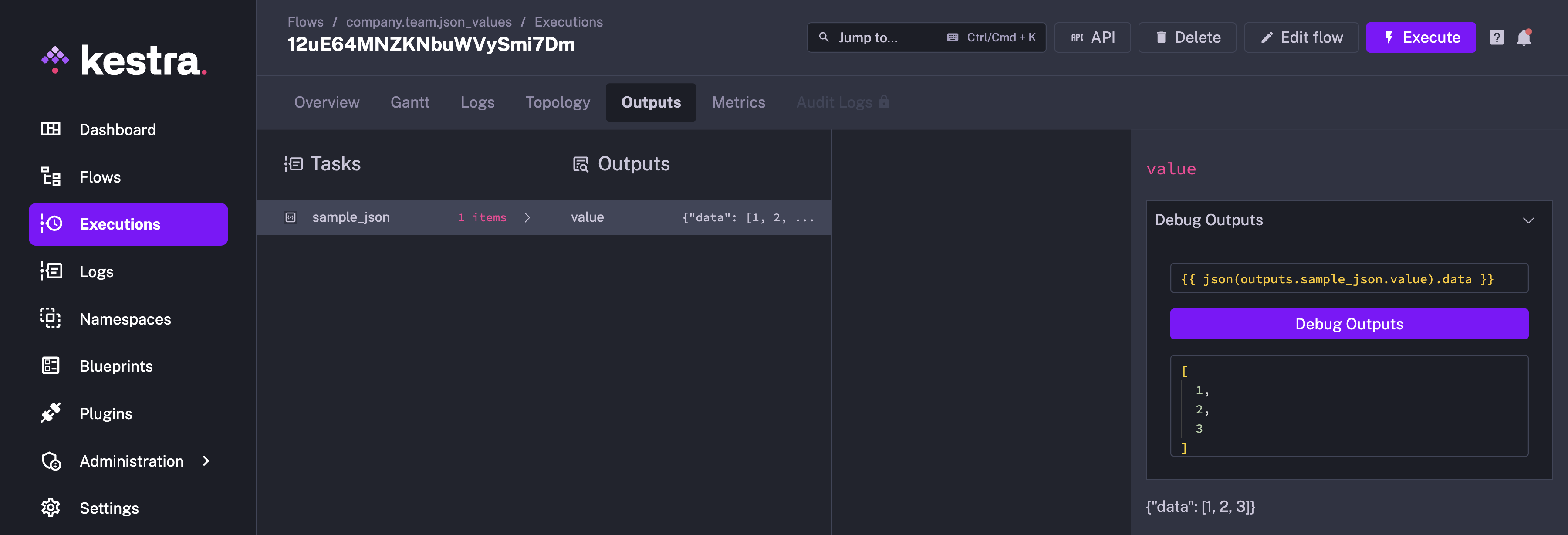
Using Debug Outputs
You can evaluate the output further using the Debug Outputs functionality in the Outputs tab. Consider the following flow:
id: json_values
namespace: company.team
tasks:
- id: sample_json
type: io.kestra.plugin.core.debug.Return
format: '{"data": [1, 2, 3]}'
When you run this flow, the Outputs tab will contain the output for the sample_json task, as shown below:
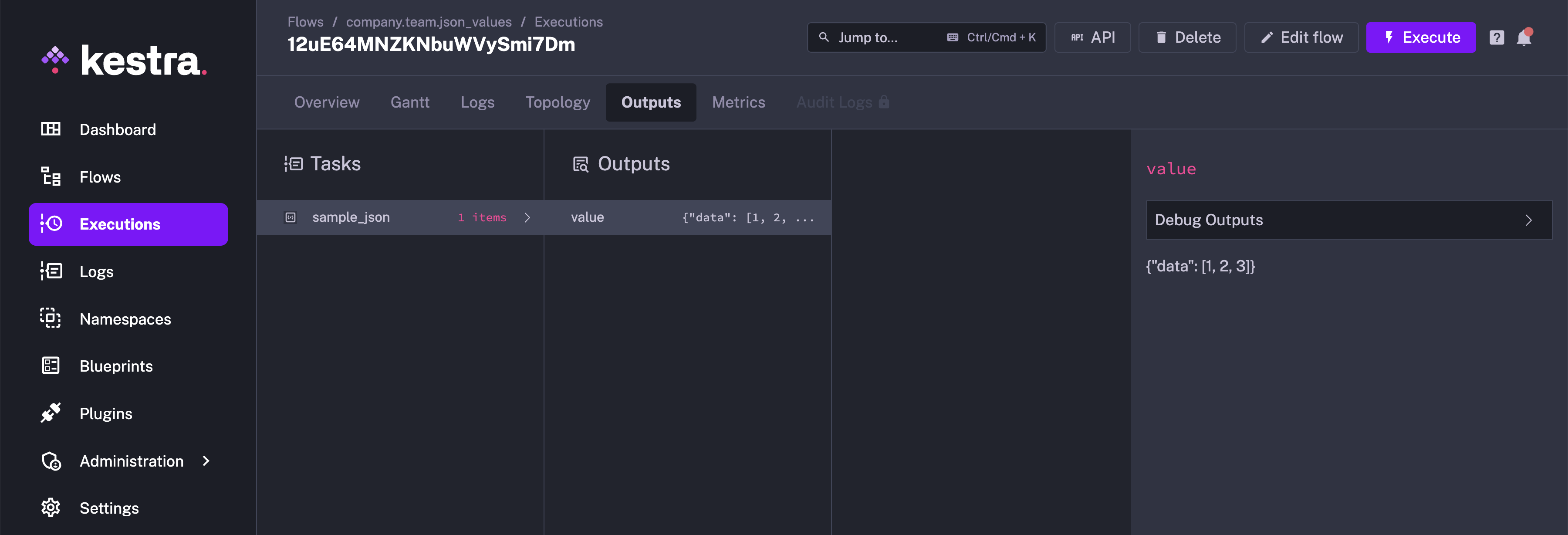
You can select the task from the drop-down menu. Here, we will select "sample_json" and select Debug Outputs:
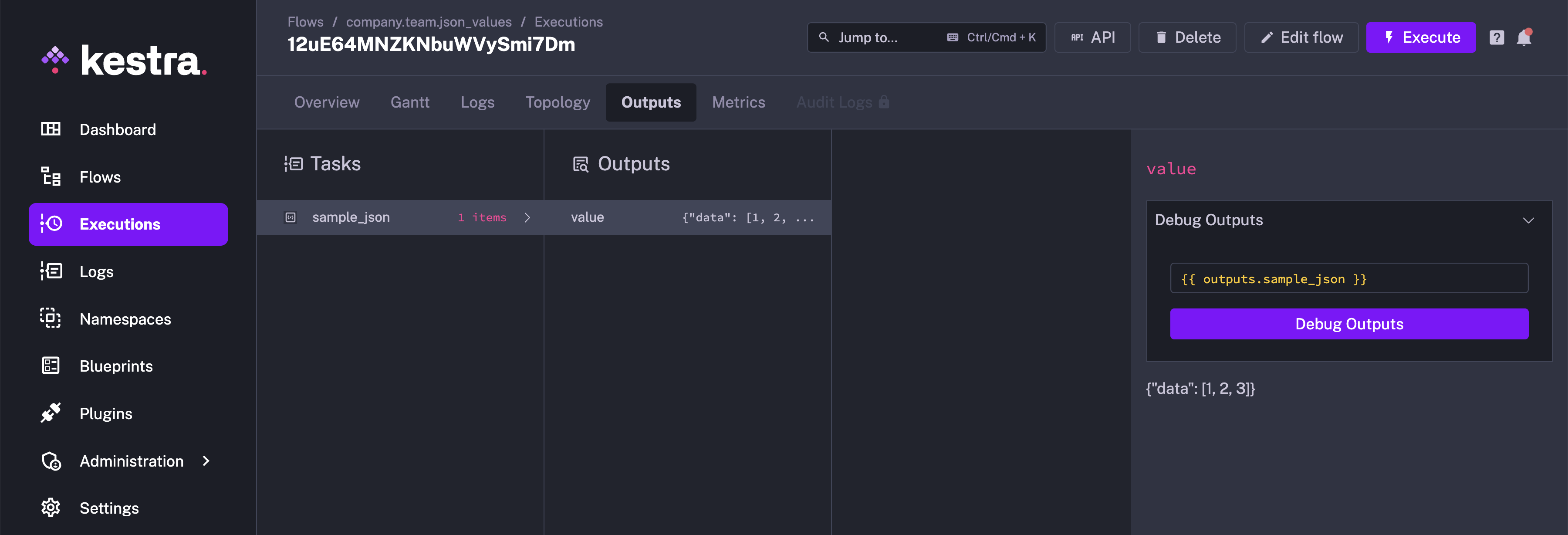
You can now use pebble expressions and evaluate different expressions based on the output data to analyse it further.
Note: This was previously called Render expression
Was this page helpful?